
According to AIIM & Accenture Surveys report – in the next few years’ volume of information produced by our civilization will be doubled. Report also points, that arrangement will be split into 20% of structured data and 80% of unstructured data. Following this analysis, Gartner (Feb 2008) points that “By 2009 ECMs will become the focal point for empowered managers, enabling proactive or reactive responses to opportunity and threat scenarios”. IBM FileNet Content Manager conquers these challenges by combining the enterprise content and process to substantially improve the availability and agility of content in business functions and processes. Content Manager combines comprehensive content management along with specialized document management capabilities – especially active control over unstructured corporate assets. FileNet Business Process Manager controls and manages the flow of work throughout your business by streamlining, automating and optimizing business processes. It has the flexibility and scalability to handle the most complex business processes – involving millions of transactions, thousands of users and multiple business applications. Such a sizing involves The FileNet P8 family of products – to provide robust software services, a critical requirement for highly available systems. Software robustness, however, is not sufficient when systems can fail due to both hardware and software problems. In official guidelines IBM recommends using commercial high-availability solutions that address the failures that can occur in a complex networked environment. All of the FileNet P8 components leverage several technologies to maintain availability in the event of a local component failure such as the loss of a server, disk, or network device – which are farming at the Web server layer, and clustering technologies for backend services and databases. One of this paper’s goals is to focus on new methodology regarding this area.
Web server farms
Web server farms provided through hardware or software load-balancing technology enable high availability at the Web server tier. A farm is a set of load-balanced servers that are clones of each other, each actively providing the same service, with the same applications and same binding to servers in the tiers below them. Farms are best practice for server tiers that are relatively static in terms of content, because that makes it easy to maintain them as clones of each other. The FileNet P8 Web-based components have been certified to operate within Web and application server farms such as BEA WebLogic clusters and IBM WebSphere clusters. These types of farms provide for server redundancy with the added value of scalability, because all of the servers in the farm are active. Application server farms can be combined with hardware-based load-balancing solutions such as Cisco routers or software-based solutions such as Network Load Balancing (NLB). A load-balanced Web server farm provides both better availability and better scalability than a single Web server. When a Web server fails, the load balancer automatically detects the failure and redirects user requests to another server in the farm, thereby keeping the service available. Administrators can increase Web site performance and capacity by simply adding servers to the farm.
Server clusters
For a complete highly available solution, Web servers and all supporting servers need to be configured for high availability. In a multi-tier architecture, this includes application servers implementing business logic and any servers in the data tier (for example, databases). These servers are typically data-driven, with large amounts of data, and a constant stream of new or modified data. Using a server farm approach with data replication is not as appealing for these tiers because of the difficulty in maintaining data synchronization in the face of frequent change. Instead, server clustering products are used which are based on the concept of shared data storage instead of a separate storage device per server. In this case, two or more servers share the same highly available data storage device, such as a SAN, NAS, or RAID disk array. The shared storage device incorporates redundant copies of the data but appears as a single
shared drive to the servers, thereby avoiding the need for data replication between servers. Only one server in a data-driven cluster is active at a time, unlike a server farm, in which all servers are constantly active. Thus there is no load-balancing requirement in a server cluster. Instead, clustering software is employed to detect a failure on the active server and trigger a “failover” to the passive server. The passive server is also running the clustering software in a standby mode, waiting to take over in the event of a failure on the active server. The clustering software thus has three responsibilities: monitoring the health of key applications and processes on the active server, stopping the applications and processes if a failover is required, and starting the same applications and processes on the passive server when it becomes active in a failover.
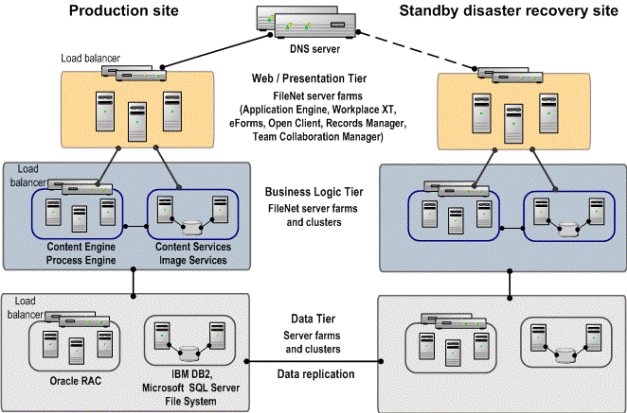
Pict. Standard P8 architecture (Production and DR)
Real System Infrastructures
In my professional career I have a chance to examine and observe large Enterprise Content Management solutions. Based on two examples I will render latest methods and techniques provide distributed and high available solution for ECM systems.
Project REDA (Telekomunikacja Polska)
The main implementation goal for Repozytorium Elektronicznych Dokumentów Abonenckich REDA (Repository of Subscriber Electronic Documents) system was to facilitate the business processes at TP S.A. as well as open the possibility to introduce changes to those processes in a quick and flexible manner. One of the key system tasks was to facilitate the flow of documents to TP consultants’ workstations which had so far reached the consultants in a paper form. The swap from paper documents to electronic images created in the scanning process as well as remote access to documents provide for on-line implementation of document processes and parallel work over the same document . These possibilities offer total control over the punctuality, with which the issues are dealt. Introduction of logical document queuing architecture for processing as well as task allocation algorithms help to optimize the time consumed over subscribers’ issues. Document access time has been shortened as well. System is designed for 3 thousands of users operating 24/7. This involves applicable architecture and system scaling. Horizontal scaling, also referred to as scaling out, indicates that the performance and throughput of the total system can be increased by adding physical servers.
Architects of REDA make possible to implement horizontal scaling just by installing the appropriate software components on the additional machine and configuring the application to use them. By installing new machine or virtual node with instance of FileNet Process Engine – it is possible to address more computing power to increase processing task’s functionalities. As workload is added, the load-balanced system adapts and spreads the work out over the available farm of servers, all with minimal overhead. As the system is required to handle more workload, additional servers can be added as needed. Conversely, if resources are needed for other business purposes, servers can be removed. The ability to dynamically add or remove servers from the farm based on business needs leads to reduced total cost of ownership, because the improvements are incremental and use multiple, low-cost servers where and when they are needed. This avoids a large, up-front investment in hardware aimed at handling anticipated workloads much larger than current requirements.
The PE’s architecture allows for a true farm configuration, in which there is no direct communication between PE instances. This reduces overhead and allows for maximum horizontal scalability, since the only bottlenecks are shared resources such as the network and RDBMS. The horizontal scalability of a system can be defined as the ability of that system to handle additional workload by adding a proportional number of servers to the system. In an ideal system, such scalability would be perfect, in that the cost (measured in CPU computation) of each individual transaction would be constant, and there would be no limit on the number of servers that could be added. In practice, however, considerations such as communication overhead and shared resources become more and more significant as the number of servers grows, and eventually come to be the dominant factor in determining the behavior of the system. The bigger the ratio between the maximum-sized system and the basic system, the better the scalability is defined to be. During the implementation final phase set of tests was run against the system. A purely Business Process Management workload was generated by an application developed by IBM FileNet using standard, publicly-available APIs. That application issued queue query and dispatch requests to the PE servers, and was hosted on a set of 4 Windows machines. A sequence of tests was run, varying the number of PE instances configured and the workload applied to the system by the load-generators. All of the test were run according to specified WorkFlow Map
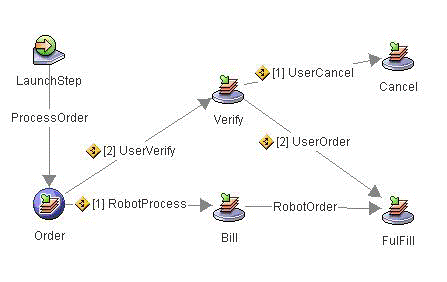
Pic. Testing Workflow Scenario
The following chart shows the throughput of the system as the number of PE servers and workload were increased. Throughput was measured in transactions per second sustained by the entire farm of PEs.
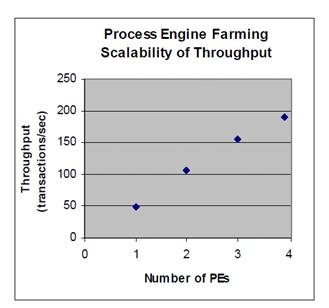
Pic. Scalability of throughput. The throughput rises close to linearly as PE servers are added to the system
In an ideal system, as resources were added, the sustainable throughput would increase in exact proportion. In real systems, communication overhead and shared resources prevent this. Scaling efficiency can be defined as the percentage of the ideal workload that is achieved. In the current system, with 4 PEs configured, a scaling efficiency of approximately 90% was sustained. Together with the solid response time consistency this suggests that the performance was not bounded by any inherent architectural bottlenecks in the PE, and that the strong scalability of the PE under load-balancing technology should extend to significantly larger workloads.
As PE servers were added to the system, workload was added. In characterizing the scalability of this process, it is important to measure not only the overall throughput sustained, but also the amount of processing power the system spent producing that workload. In a highly-scalable system, the CPU utilization will grow proportionally. The way to see that growth is to look at the utilization of the aggregate system.
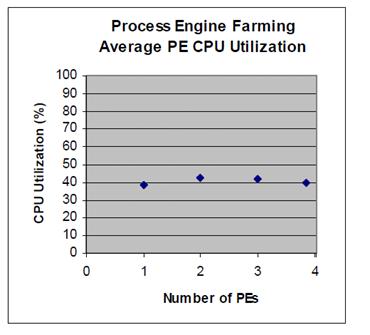
Figure 2 Average PE CPU Utilization. The average CPU utilization of the PE farm shows little variation as the number of PEs rises.
The pattern shown in the chart indicates a growth rate concomitant with that of the throughput, meaning that the system shows solid scalability. The PEs in the farm had work allocated to them by an F5 BIG-IP LTM. In each case (2, 3 and 4 PEs) that allocation resulted in a well-balanced workload. The following chart shows the CPU utilization of the different PE servers in the 4-PE case. Cases with fewer PE servers were similar. Part of the Enterprise Content Management (ECM) challenge is the need to manage business processes effectively. Horizontally-scalable systems meet this challenge and are able to minimize total cost of ownership by providing low-cost, highly efficient methods of expanding the system’s processing power. The IBM FileNet P8 Process Engine (PE) allows real horizontal scaling through the use of server farms, and this study presents test results demonstrating the scalability of such configurations. The data in this paper strongly suggest that farms of PE servers significantly larger than those under test could be maintained.
The scalability of the system can be seen in this study in two main ways: (a) the throughput climbs with nearly-linear growth through 4 PE servers, and (b) the CPU cost and response time remain relatively constant over a wide range of workloads. For systems with predictable growth in throughput capability and minimal change in CPU cost, confident extrapolations can be made to workloads greater than those tested. Constant or only slowly-growing CPU cost is an indication that system components are not starved for resources, meaning that there is no fundamental architectural bottleneck in the software. Total cost of ownership is reduced in this way, as hardware allocations can be increased to handle anticipated workloads that are larger than an enterprise’s current load, and reconfiguration of the overall architecture can be avoided. A different approach to horizontal scaling is the concept of a server farm, sometimes referred to as a cluster of nodes, especially in the context of J2EE application servers. The farm consists of multiple instances of a designated server components (such as the Content Engine) that are all identically configured. Although it is possible to configure an application to use one particular server of the farm to get requests processed, in most cases, horizontal scaling introduces a load balancing mechanism, which is used to distribute incoming requests across the servers in the farm for processing. The advantage of this approach is that it can also deliver high availability, if the load balancing device recognizes failed nodes in the farm and excludes them from the load distribution. This solution is rendered in next example
Project UPCase (UPC Polska)
UPCase was a dedicated system of Document Management and Business Process Management. Main purpose of this system was to automate most of the customer’s business processes focused on documents (paper and electronic). Supplier have build and customize platform based on FileNet P8 functionalities. The power of all FileNet installation is to understand client’s business model and map workflow maps to process engine business algorithms. In this project one of the key phases was analytical workshops with clients. After this step Supplier been able to build an optimal data structures and task flows. After digitalization of client’s business there were modeled Business Intelligence layer to present key data and to react for critical situations. System was designed for 500-600 users working on shifts 24/7. Standard logical components of P8 platform was applied:
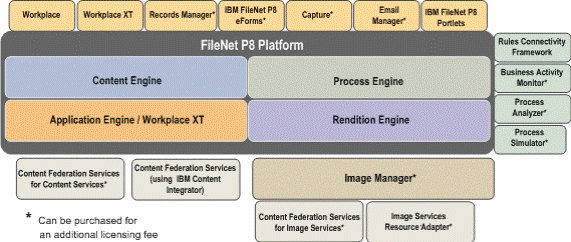
Pict. Standard FileNet P8 platform design
In this system’s architecture to fulfill the entire customer requirements server farm scaling out solution was designed to provide a service to an end-user with as little perceived downtime as possible. If a system component fails for any reason, the high availability solution ensures that another component takes over for the failed component, and that the newly composed system will maintain the same machine identifications (host names and IP addresses) as the system prior to failure, minimizing the disruption to the user.
In this case server farm was built. A server farm is a group of identical servers accessed through hardware or software load balancing technology. All the servers are active, provide the same set of services, and are effectively interchangeable. A load balancer distributes incoming client requests over the servers in the group. Upcase system consists of farming CE. Content Engine is web application that is processing-centric rather than data-centric, as all the servers in the farm are clones of each other. Processing logic for these components does not change often, making it easy to keep all the servers identical.
Content Engine is the central point of the IBM FileNet P8 repository. Content Engine must be highly available. If Content Engine fails, users no longer have access to existing content, and they cannot add new content. This inaccessibility occurs from API-based programs, as well as from other components, such as the Application Engine (AE) and Process Engine (PE). The importance of Content Engine must be a key factor in creating any IBM FileNet P8 HA environment. When Content Engine is unavailable, neither the content nor the processes can be routed (although in certain cases, there are still operations that will succeed, at least for users who are already logged in). In comparison, if a Process Engine fails, the users can still ingest and retrieve content from the repository. If an Application Engine fails, the Workplace application cannot be accessed; however, the repository or Content Engine can still be accessed through a custom, API-based application. In the case of a Content Engine failure, the entire repository becomes inaccessible. Because Content Engine is implemented as a Java 2 Platform, Enterprise Edition (J2EE) application running within a J2EE application server, it can exploit all the scalability and high availability options that are available for J2EE application servers.
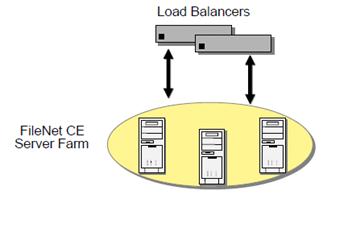
Pict. Basic server farm setup
A hardware load balancer is an appliance that is specifically designed to distribute a huge number of incoming requests across individual servers (physical or virtual). Typically, the method of distribution can be configured (such as round robin or weighted round robin), and sophisticated units can monitor the back end server load and change the distribution rules accordingly to ensure approximately even loads on the balanced servers. Some hardware load balancers can be extended with additional network ports and provide a huge variety of configuration options, such as considering server processor utilization or the number of connections to an individual server. When building a highly available system, use at least two load balancers to avoid a potential single source of failure because when the hardware load balancer goes out of service, no requests are forwarded to the IBM FileNet P8 servers, and the complete application can no longer be used. At least the load balancer must be hardened by ensuring that critical components, such as network card and power supply, are redundant.
The Content Engine is a J2EE implementation. Therefore, Content Engine supports the standard approach for scaling J2EE applications by establishing a farm of nodes across which the load can be distributed. Additionally, the Content Engine hosts two Web service listeners: for the Content Engine (CEWS) and for the Process Engine (PEWS). Both listeners are the entry points that clients can use to communicate with either Content or Process Engine using their Web services API and are running in the Web container of the application server.
Horizontal scaling is the preferred option for applications that run in the context of a J2EE application server because it also provides high availability at no additional cost. Horizontal scaling establishes a farm of Content Engine nodes. In this particular scenario hardware balancer was used for balancing the load across the Content Engine servers, configuring the Content Engine API to use the Web Services transport (WSI) for each client that accesses the Content Engine using the hardware load balancer is required:
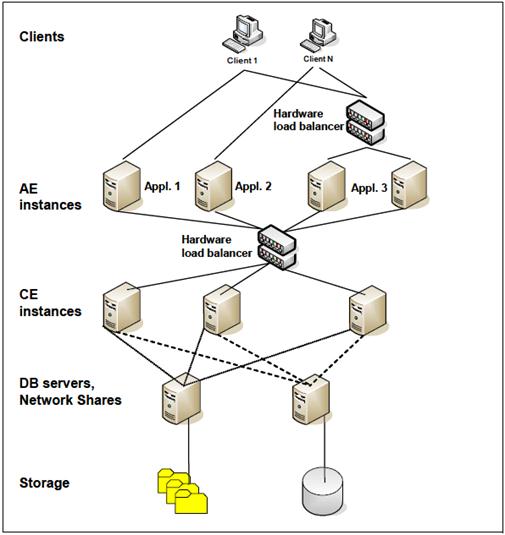
Pict. Detailed UPCase distributed architecture
In this project architects used the virtual host name that the load balancer provides in the configuration of a Content Engine Web Services API on the client. Because the communication between a client and the Content Engine is stateless, it is not required to configure session affinity on the load balancer.
During final acceptance test phase set of test was run against Content Engine.
The workload used in these tests simulates high volume document creation and retrieval. Testing was conducted using a load generation application developed by IBM. The application is designed to create documents and ingest these documents into the IBM FileNet P8 Content Engine. In addition, the application is able to retrieve documents from the IBM FileNet P8 Content Engine. The load generation application relies on publicly-available FileNet P8 Java interfaces. These interfaces use Enterprise Java Beans (EJB) to provide a client/server interface between the load generation application and Content Engine (CE). All document content was stored in the CE server using fibreconnected, external IBM file storage. WebSphere was the J2EE application server used to host Content Engine instances. Environment allowed to use maximum 24 instances of CE.
Sequences of tests were executed, each test varying the workload applied to the system by the load generator application. The tests ingested and retrieved 30 KB documents, along with the associated document object properties. Numerous loadgenerating CE instance were used, each of which submitted document object properties and content using the batching features of the IBM FileNet P8 CE Java interface. There was no interoperation delay (i.e., think time) between requests.
Statistics were gathered after all load generating applications were started and the test environment achieved steady state as gauged by CPU utilization and throughput rates.
The results in this paper present the ability of the Content Engine solution stack to handle increased workload demands with excellent performance. The data shows predictable, smooth system utilization as the workload was increased within the tested range. Document creation and retrieval rates were measured, and, in the following sections, the scalability of these operations is presented in terms of documents per second and CPU usage. The system exhibited performance, with nearly-linear scalability throughout the tested range.
The first chart presents the measured throughput and CPU utilization for document retrieval. It shows the retrieval throughput in documents per second as a function of the CPU utilization. This throughput chart demonstrates the ability of the Content Engine to scale, with the system handling a large number of document retrieval requests. The system was able to sustain a retrieval rate of more than 7.8 million documents per hour, a data throughput rate of more than 65 megabytes per second. The error bars in the chart are an estimation of the expected variation in presented data, based on trends observed over multiple test runs. The values presented are expected to vary typically by approximately 10% from the indicated average, although greater variation could occur.
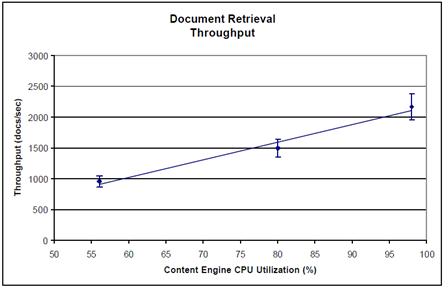
Pic. Document Retrieval Throughput of Content Engine solution stack
The following chart shows the ability of the Content Engine to scale and handle a large number of concurrent document ingest requests. The IBM solution stack was able to sustain a document creation rate of more than 5.6 million documents per hour. Again, the error bars represent the expected variation in the data, although greater variation could occur.
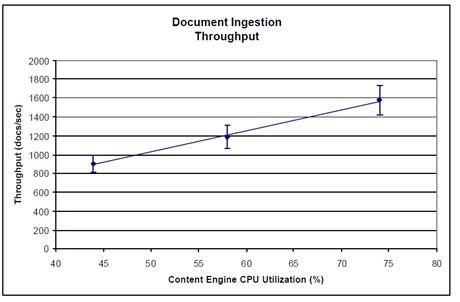
Pict. Document Ingestion Throughput of Content Engine solution stack
The data results show strong scalability during document ingest. A throughput rate of more than 47 megabytes per second was maintained. The smooth growth rate suggests that additional system resources would result in increased throughput.
This study presents test results demonstrating ability of distributed computing in the IBM FileNet P8 4.0 Content Engine (CE), the core set of content services and key repository offering underlying all IBM FileNet P8 product suites. The test results illustrate the CE’s ability to make use of the IBM solution stack and available system resources in a large, enterprise-class environment. The IBM FileNet P8 architecture provides a highly scalable framework, allowing functional expansion to manage enterprise content and process challenges. The framework provides extensive process control, with consistency across the enterprise. The IBM FileNet Content Engine provides the core content and catalog services for the P8 platform, and is the key repository offering in the Content Manager suite. The Content Engine underlies all IBM FileNet P8 products.
However rendered previously options for scaling the solution isn’t the only option. To explore thoroughly this subject I have to mention about vertical scaling of P8 solutions.
The concept of vertical scaling, which is also often referred to as scaling up, relies on the idea that adding hardware resources, such as memory or CPU power, to a given server results in the ability to handle an increased load. Depending on the nature of the application that is running on this server, it might be possible that the additional resources are effectively used automatically or just by changing some configuration parameters (for example, the number of threads that are used internally).
In the case of a J2EE application, server infrastructure scaling vertically requires, in most cases, to run multiple instances of the application server on the physical machine to make use of increased hardware resources because each instance of a J2EE server runs in a single Java Virtual Machine (JVM), and the concurrency limitations of a JVM process prevent it from fully using the processing power of a machine. Also, the amount of time that is required for a garbage collection limits the amount of memory that can be used efficiently by a single JVM.
Picture below illustrates how horizontal and vertical scaling can be used in combination to optimize the usage of resources on a physical server. In this example, on each machine, four instances of the J2EE application server are started and into each application server instance one instance of the application is deployed. As a result, twelve entities of the application are available to handle incoming requests.
Picture below shows Combination of vertical and horizontal scaling for J2EE applications Certainly, there is a restriction in the number of J2EE application server instances that can run in parallel on a single box without affecting each other in terms of shared system resources, such as CPU, memory, or networking.
Vertical scaling for J2EE applications is an option to reduce the hardware footprint for the solution. By combining horizontal scaling and vertical scaling across three physical machines, as shown in picture, high availability can be achieved.
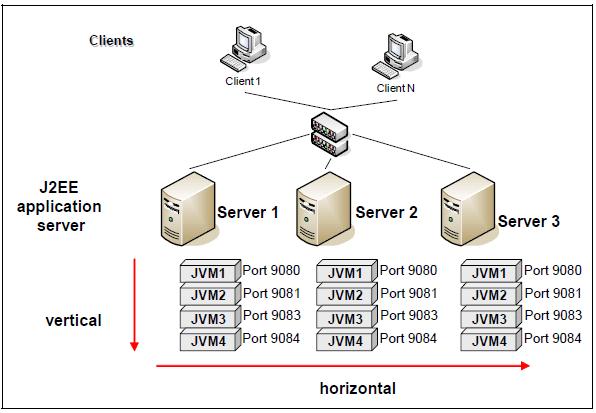
Pict. Combination of vertical and horizontal scaling for J2EE applications
Certainly, there is a restriction in the number of J2EE application server instances that can run in parallel on a single box without affecting each other in terms of shared system resources, such as CPU, memory, or networking. Vertical scaling for J2EE applications is an option to reduce the hardware footprint for the solution. By combining horizontal scaling and vertical scaling across three physical machines, as shown in previous picture, high availability can be achieved.
Conclusion
In this paper I have presented brief overview of methods and techniques to adopt distributed computing into real life Enterprise Information System solutions. I have pictured solution based on IBM FileNet P8 platform, dedicated to large population of users – especially focused on clustering and farming of core FileNet modules. Discussed here techniques and devices are most advanced and latest solution existing at the market. I have introduced core FileNet modules and presented real architectures which are build Content Management and Business Process Management solutions upon distributed architecture. Additionally I have attached practical observations from system’s architect and administrator point of view.
Bio
Lukasz Osuszek, IBM
Associated with theIT industry for over 10 years. Author of numerous scientific articles and technical books. He gained experience by providing quality solutions Document Management Systems and Business Process Management. An important element of these projects was to analyze the business requirements, system architecture design, optimization of processes and applications. The main objective was to increase the competitiveness of organizations by integrating people, processes (ways of doing things), and create an optimal software.
REFERENCES
AIM & Accenture Surveys, 2007 report, Gartner, Gartner Business Process Management Summit 2008 IBM FileNet P8 System Overview, GC31-5482 IBM FileNet P8 High Availability Technical Notice, GC31-5487 IBM FileNet 4.0 Installation and Update Guide, GC31-5488 IBM FileNet Image Services, Version 4.1, Microsoft Cluster Server Installation and Upgrade Procedures for Windows Server, GC31-5531-01 IBM FileNet Image Services, Version 4.1, VERITAS Cluster Server and VERITAS Volume Replicator Guidelines, GC31-5545 IBM FileNet Image Services, Version 4.1, Installation and Configuration Procedures for AIX/6000, GC31-5557-01 IBM FileNet Image Services, Version 4.1, Release Notes, GC31-5578-03 IBM FileNet P8 Content Federation Services for Image Services, Version 4.0, Guidelines, GC31-5484-01 IBM FileNet Image Services, ISRA, and Print Hardware and Software Requirements, GC31-5609-04High Availability, Scalability, and Disaster Recovery for DB2 on Linux, UNIX, and Windows, SG24-7363



