
The details include search engine core components that work under the hood in tandem to generate the search results based on user requirements. Who are these core components? What’s their purpose in Search and answers to all these you would find in this artifact. A brief summary of package products and a list of search engine packages that are available out of box. This document is a consolidation of the search engine and frameworks and a write up on package search engine from FAST ESP.
The Search Engines Laden:
Search engines are available in many shapes and sizes with a varied list of features and functions. This document explains the essential ingredients of a search engine and what makes search engine search thro’ the content repository. Search engines in a software application that would index thro’ the enterprise repository and generate a results in a predefined format. Search engine along with the frameworks components are generally package software. Set of features build into the search engines are based on 80-20 %. 80% of the features are in-build rest 20% thro’ customization, configuration and tuning. Primarily 2 types of the customizations can be done on search engines. One is thro’ programming APIs other is thro’ configuration XML and administrative interfaces.
The search framework provides the following capabilities
- Retrieve or accept content from web sites, file servers, application specific content systems, and direct import via API
- Analyze and process these documents to allow for enhanced relevancy
- Index documents and makes them searchable
- Process search queries against these documents
- Apply algorithms or business rule-based ranking to the results
- Present the results along with navigation options
Gleaming Current and Future Trends:
Search has become a core function for any organization. This is no more just a passive box in the right hand corner of the portal. Based on the knowledge of the customer trends on the website it would typically drive the environment in which it operates. The engine would index the any or all of the sources which includes content management (Web Pages, Digital Assets and Documentations), product catalogue, and campaign management, CRM, Fulfillment Billing and Assurance. Online business has evolved to an extent every dame thing is done online. Companies like IBM make 50,000 USD per minute. The click streams have become a way to generate revenues by using information access technologies to index a database on advertisements and embed them as paid results. The combo of click stream of search plays a crucial role in customer product and its context by means of cross-sell and up-sell based on historical purchase patterns across entire customer base. Companies like Google use these kinda of data to provide customized user experience based on search history. This is building the profile over time and then indexing this data and applying to future interaction of the customers.
Core Engine Framework – Stymied:
The search core framework is made up of data input, data processing, and data output elements as part of the data pipeline. This is from a very abstract level and as explained below it has more than just these 3 components working in tandem. The content is typically sources thro’ Web Pages, Content Database, Product Catagories or it could be systems like CRM, Billing Assurance. Engine provides a variety of connectors to access different types and kinda of source databases. Database, Content, Exchange and SAP systems. This data goes thro’ pipeline line elements like the document and query processing and caters to applying post processing algorithms to get the desired result sets. The indexes stored in the search are stale which means that every time one of those links are displayed as part of the results set the indexing algorithm of the engine hits the server to get the latest content over the internet. Among the core elements the crawlers (spiders) caters to one important task of indexing fresh pages based on the initial index that are archived in the search databases. This new index is stored along with content, data in the page its link.
Search Framework Architecture:
Below is a component model that highlights the key components of the search platform.
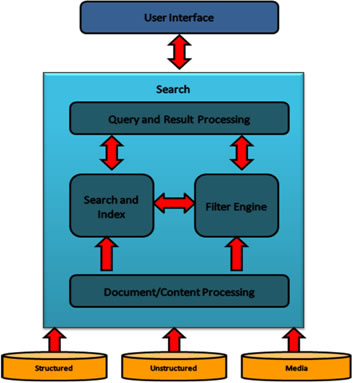 |
Figure 1: Search Engine and Framework Architecture:
This model depicts search as service that can be consumed by any application. Search provides APIs for an application to execute queries and display results lists as well as access to content sources to enable them to be indexed.
Search application integrates with the search engine and for specific business applications such as address search. In these situations business logic associated with the application is contained with the search application rather than in the search engine. The search engine manages the indexing for the content related to the application. From a business perspective capabilities include content refinement, relevancy, linguistics, query and result processing, business rules are important capabilities.
There are generally four distinct phases of the search system.
- Content Acquisition and Refinement
- Indexing
- Query Processing
- Results Processing
1. Content Acquisition and Refinement
The content acquisition system obtains content from the source and pushes the content to the indexing system. The content can be new or updated content and the system should be able to update the index incrementally based on the content triggers.
Content comes from a variety of sources and could be any one of a wide range of MIME type. Content sources will include database systems, content management systems, file systems and the type will include web sites, office documents, XML data, pdf’s, music, video, and pictures.
The content API supports variety of connectors as well as supporting integration of applications via c++, Java and .Net. The Document processing component allows formatting, categorization and analysis processing to occur on the data before it is committed to indexing and matching.
The API enables structured and unstructured content from the following sources to be processed:
- Messaging systems
- VoIP telephony systems
- Video
- Music
- Web content
- File stores containing Office documents, PDF’s etc
- Databases including Oracle, SQL, DB2
- Content management and Document management systems
- Data in XML format
2. Indexing
The Search engine provides a core indexing and search capabilities. This process transforms the content into an index that is designed to provide accurate results and also value add features such as categorization and entity based navigation. A filter engine provides real-time filtering and alert capabilities based on stored alert queries.
3. Query and Result Processing
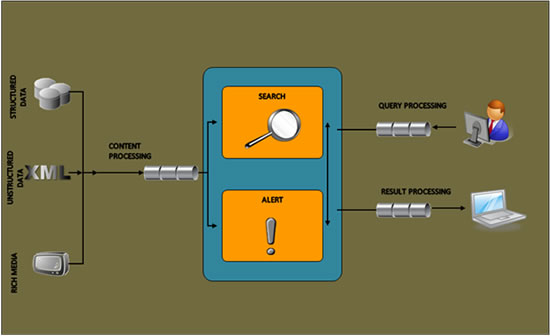 |
Figure 2: Query, Result and Content Processing Pipelines
Once a user enters their query the search engine processes the query to enable the matching in the index to be accurate. Keyword matching is no longer adequate as the algorithm for delivering accurate results. Other more sophisticated algorithms such as lemmatization, phrase detection, n-grams may also to be applied.
A user interaction may, in fact be several queries processed in parallel to deliver a highly personalized experience for the user. The query and results processing components provides pre-processing of queries and post-processing of the result set. Pre-processing includes query modification such as spell checking. Post-processing would include formatting, sorting and clustering of results.
The query API provides easy integration with search applications. The query API client can be constructed using C++, java or .NET (C#). HTTP client applications can to query the search index. Results can be retrieved as XML or text formatted result fields. The results can be tailored for the interface and provide users with the ability to organize the result list. Users also expect other options like ‘more like this’, ‘more by this author’ etc to be available.
Package Products – Comrade:
What do I do with Search then ? Let talk about real world. A package product is like a bon voyage it would get you from one end point to another as promised. But there should is a blessing in disguise as you got to know the internals well enough to get the best out of the package product. Generally with package software’s each vendor would have its own Sizing methodology based on the counts of indexers, crawlers, documents, nodes and this gives us the details on the estimates in terms of effort requirement. Typically the process involved for building solutions using package implementations consist of following phases Envision -> Architect -> Integrate -> Evolve. Search would be clubbed into a larger context along with the other piece and the major ones include Portal, Content, Identity Services, and Operation Management. Package products are hot choices when it comes to time to market parameter and gives a breather to the stakeholders in terms of this 80-20 law. Estimations are one of the key areas of package products and different vendors provides a set of tools for estimating based on varied requirements like scope, scale, performance considerations.
Data Point:
- Identify Roles, Access, LOB, Channels.
- Classify Requirements
- Validate Requirements against Telstra Security and Legal Compliance
- Simple Search (Content Sources)
- Advance Search (Boolean operation, wild cards, special characters, metadata search)
- Ranking Profile (Static Vs Dynamic Ranking, Ranking Model within Logical Group)
- Search Result (Result Clustering)
- Indexing (Content Sources and types, Restricted Domains, https and SSL Pages)
- Linguistics (Dictionary Management, Spell Checker, Case Sensitivity)
- Integration (Federated Search)
- Administration – Fast UI and SBC



